- ホームページ
- シェアウェア
- Development
- Help Tools
- ファイルサイズ: 238458 KB
- 価格: $749
- ダウンロード: 293
- 作者: Extract Data from PDF C# Tech Team
- 説明:
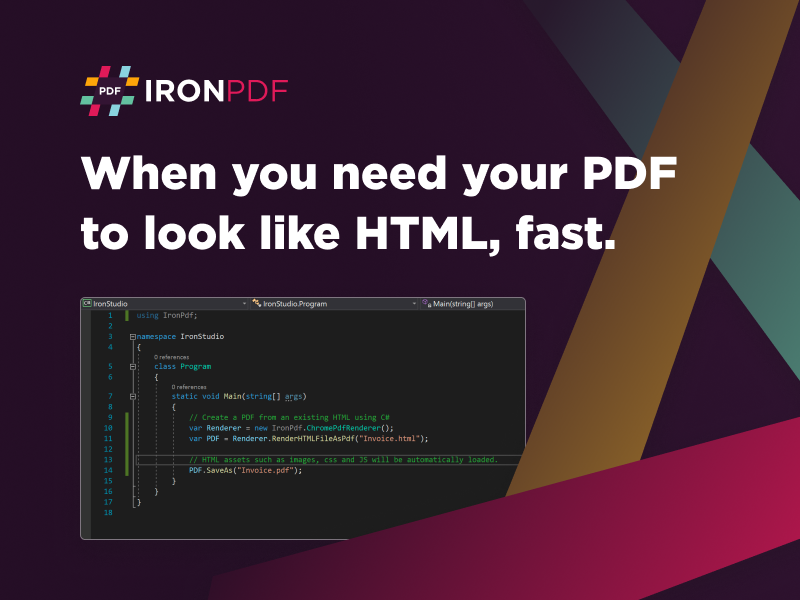
This C# PDF library offers various methods to extract data from PDF files. It allows you to extract text, images, tables, and even metadata from PDF documents. Whether you need to extract specific sections, entire pages, or structured data, the library provides the necessary tools to accomplish the task.
The library also offers additional features to enhance the data extraction process. It supports OCR (Optical Character Recognition) technology, which enables you to extract text from scanned PDF documents. It also provides advanced text search capabilities, allowing you to locate specific data within the PDF files.
Using the C# PDF library to extract data from PDF files is straightforward. With its intuitive API, you can easily navigate through the document structure, extract the desired elements, and save them in the desired format, such as text files, Excel spreadsheets, or databases.
The library is easy to integrate into your C# project, and its API is well-documented, providing detailed instructions and examples for data extraction tasks. You can find more information at https://ironpdf.com/blog/using-ironpdf/how-to-extract-data-from-pdf-in-csharp/.
Leveraging a C# PDF library for data extraction from PDF files offers a reliable and efficient solution. With its range of functionalities and ease of use, it simplifies the process of extracting valuable data, saving time and reducing the risk of errors. Whether you need to extract text, images, or structured data, the C# PDF library provides the necessary tools to handle various data extraction requirements.
-
- 無料ダウンロード